作者 | GenAICon 2024
2024中国生成式AI大会于4月18-19日在北京举行,在大会第二天的主会场AIGC应用专场上,行者AI创始人&CEO尹学渊以《生成式AI赋能智慧文娱及教育新生态》为题发表演讲。
尹学渊谈到内容创作领域长期存在“不可能三角”的问题,即质量、成本、效率三者之间永远无法达成平衡。而生成式AI的出现有望打破这一僵局,为教育、文旅行业开启了交互式、沉浸式新体验。
行者AI在多模态领域进行了广泛探索,将美术大模型和音乐大模型用在实际落地的“最后一公里”阶段。尹学渊强调了大模型与特定领域工作流程紧密结合的重要性,如果工作流程整合不当,一些看似功能强大的产品会在实际落地应用中问题频出。
工业化AI与消费级娱乐AI的差异可以概括为三个关键特性:一致性、可控性、高精度。根据真实客户反馈,行者AI的“行者丹炉”以及“图刷刷”工具可将产品策划、美术总监、原画师、3D组、运营/美宣等工种的工作效率提升3-5倍。
以下为尹学渊的演讲实录:
我的原定主题为“生成式AI在文娱和教育领域的探索”,但主办方认为这个标题过于谦逊,于是为我加上了“赋能”二字。今天我的分享将主要以案例为主,向大家展示我们是如何利用生成式AI进行创新实践的。
首先,请允许我做个简短的自我介绍。我自认为是一名连续创业者。2013年,我联合创立了游戏公司龙渊网络。2016年,我们在龙渊网络内部成立了AI实验室。到了2020年,我们将AI实验室的产品独立出来,分拆成一家AI公司。
我们公司专注于AI的应用层面,多年来一直在这个领域深耕。在生成式AI的概念尚未普及之前,我们就已经开始研发AI音乐、AI美术和AI智能体等产品,这些产品如今已在多个场景中得到应用。
今天我将分享的内容聚焦在文娱和教育这两个行业。
一、生成式AI的关键作用,打破内容创作“不可能三角”
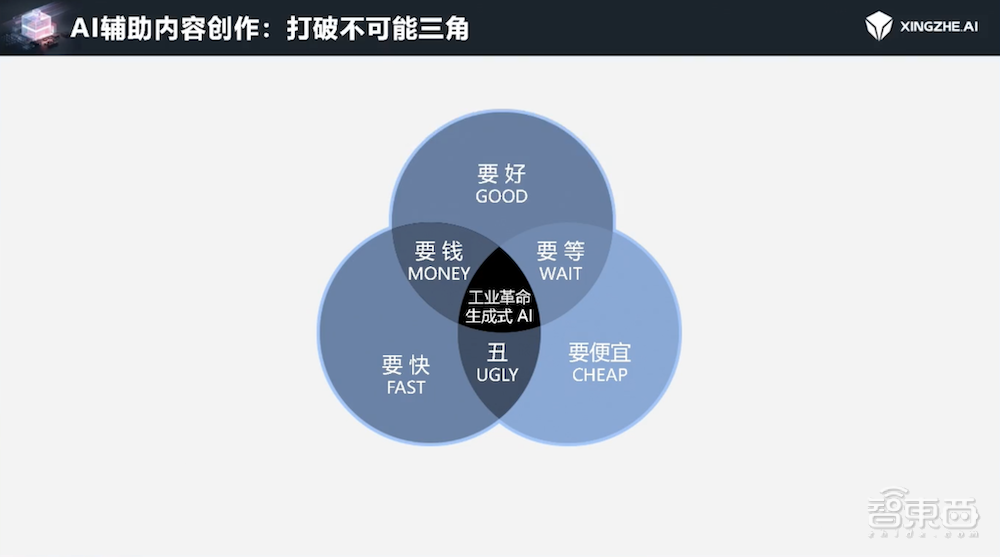
我们所有机会的起源都可以追溯到这张图所展示的原理。在过去,内容创作领域存在着一个所谓的“不可能三角”。在这个三角中,质量、成本和效率三者之间似乎永远无法达到平衡。
通常情况下,如果追求高质量的作品,那么成本必然高昂,且创作过程缓慢。如果你想要快速获得成本低廉的成果,那么最终产出的内容很可能在美观度上不尽如人意。如果你既想要高质量,又希望快速完成,那么唯一的办法就是增加投入。
你会发现,在生成式AI出现之前,这个“不可能三角”一直是内容创作领域的一大难题。
生成式AI的主要作用就是打破这个“不可能三角”。现在,我们可以在保持作品质量的同时,实现快速且成本效益高的创作。
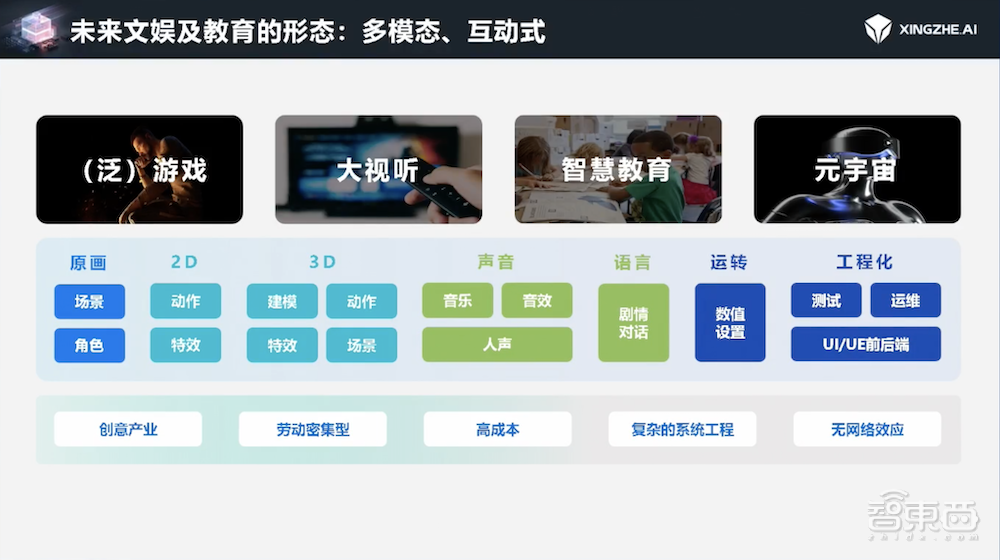
在我看来,所有的机会可以用两个关键词来概括:多模态和互动式。特别是当我们发现生成式AI技术解决了传统内容创作的“不可能三角”问题之后,许多之前只能想象而无法实现的事情,现在已经有了实现的可能。
无论是游戏、大视听、智慧教育、元宇宙,这些领域都可以分解为2D、3D、声音、语言等不同的工程化组件。随着生成式AI的革命性进步,我们现在能够在这些领域实现多模态和互动式的应用。至于什么是互动式,我将通过一些案例来具体展开说明。
这个机遇的核心在于,过去在内容创作过程中,我们总是面临着高成本和低成功率的双重挑战。在这种背景下,商业压力使得大家不得不将注意力集中在提高付费率和转化率上,很难真正从人类真善美的角度出发去设计和创造内容。无论是游戏还是影视剧作品,最终都不得不为了快速回收成本而牺牲某些价值。如果连成本都无法回收,那么这种商业模式就难以为继。
传统的教育、医疗、宣传和文化传播等领域,虽然非常值得投入,但高昂的成本限制了我们的行动。而今天,AI技术的发展为我们带来了新的机遇。这就是我想要强调的点。通过AI技术,我们可以在保持高质量内容创作的同时,降低成本,提高成功率,从而为这些领域带来更广阔的发展空间。
二、美术、音乐大模型落地“最后一公里”,将真实用户平均效率提升3~5倍
行者AI在多模态领域进行了广泛的探索和尝试。我们的美术大模型解决了很多基础性问题,也带来了很多新的可能。
然而,在将这些技术应用到实际工作中的最后一步,即“最后一公里”阶段,我们发现所有大模型都必须与特定行业和领域的工作流程紧密结合。许多产品看似功能强大,但在实际应用中却问题频出,难以落地,这是工作流程整合不当所致。
从美术层面来说,我们通常会在每个环节使用不同的工具和算法来解决问题,这些环节包括美学设计、还原度、创意构思、用户界面设计、图标制作、原画创作、3D建模以及特效和动作设计等。
并不是说我们可以通过一个包罗万象的大模型来解决所有问题,实际上这样做是非常困难的。相反,我们的目标是开发出各种不同的算法和工具,使美术从业者能够走在AI技术的前沿,掌握并有效利用AI技术,而不是仅仅为了做出一个大模型。
工业化AI与To C的娱乐AI之间存在显著差异,这些差异可以概括为三个关键特性:一致性、可控性、高精度。这三个特性是工业化AI作为实用工具不可或缺的要素。
首先,一致性意味着AI生成的内容保持风格和特征的统一。在设计两个角色张三和李四时,他们应该各自保持独特的外观,而不是随机变成王五的样子。在实际应用中,许多产品依赖于提示词来启动生成过程,一旦提示词发生变化,生成的作品也会截然不同。
无论是文生图还是文生音乐,包括最近非常流行的一些创作工具,比如音乐,用户可能会发现,如果想要修改生成内容的一小部分,整个作品就会变成完全不同的另一首歌,美术可能因为提示词的变化,而变成一张全新的图,不可深度编辑细节,这在工业化应用中是不可取的。
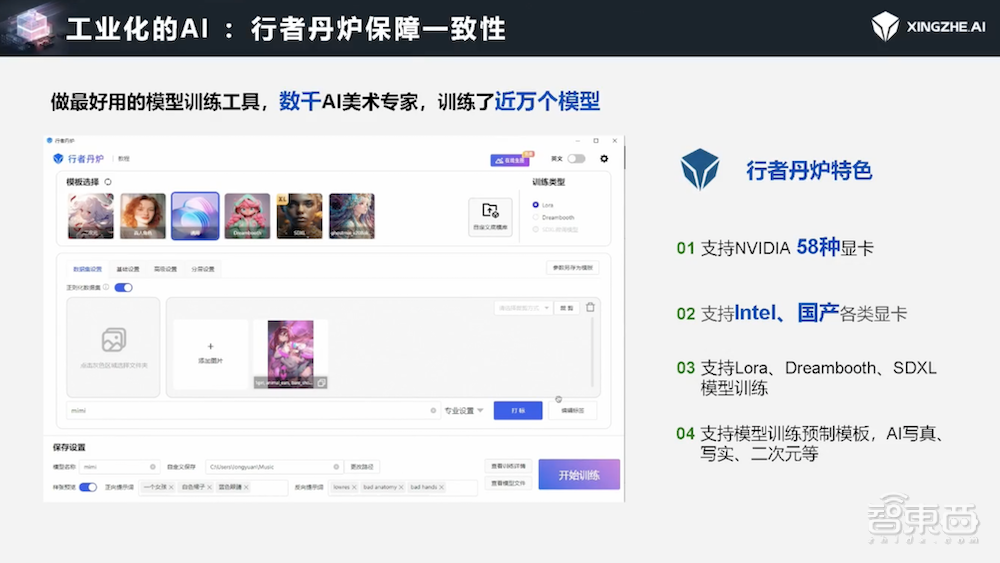
为了解决一致性的一问题,我们采用了“行者丹炉”这一概念。
大家调侃AI都在“炼丹”,我们干脆取一个名字叫“丹炉”。我们以这个比喻为基础,创造了“丹炉”这一工具,以确保生成内容的一致性。通过这个工具,用户可以迅速利用自己的素材、位置和数据标签来训练一个专属于自己的AI模型,无论是画风模型、人物模型、决策模型还是场景模型,都能轻松实现。
例如,如果你想训练一个生成你个人肖像的模型,只需将你的照片输入系统,训练出的模型就会专门生成你的肖像,无论是站立、坐着还是躺着的姿势;如果你想要模仿梵高的画风,那么生成的作品就会具有梵高的风格;如果你偏好二次元风格,那么结果也会相应地呈现二次元特色。通过这样的工具,我们不仅确保了一致性,还提高了可控性,使得最终生成的效果能够完全满足用户的具体要求。
在讨论工业化AI时,除了一致性和可控性之外,高精度也是一个关键特性。
比如一张16K的超高清的大图,使用Midjourney尝试将其缩小至4K分辨率的高清图像可能会因为性能限制而变得不可行。同样,自行搭建的Stable Diffusion在处理这种高分辨率图像时也可能因为显存不足而崩溃。 我们的算法可以做到16K,使其可以拿出去做美宣、原画。
此外,生成这样一张图并非一次性完成,而是一个分阶段、多模型叠加的过程。我们不是简单地通过输入一个Prompt然后点击鼠标就生成一张图,而是通过多个模型的叠加和分批次生成,最终合成为一张完整的图像。这表明,生成式AI必须结合具体的应用场景,并且打造与工作流程紧密结合的工具,而不是依赖一个通用大模型。
根据真实客户反馈,使用这些工具的平均效率提升了3~5倍。
这并不意味着某个行业被彻底革命或替代,而是使用这些工具的行业从业者的工作效率得到了显著提升。即使是生成一张16K的大图,也需要经过数天的多个步骤来完成,而不是瞬间生成。
当前,许多客户反馈称,他们的设计师正在转变为AI工程师,每天都在训练他们自己的模型。每个人都希望拥有自己独特的画风,每家公司也都不希望自家产品的设计看起来千篇一律或被指责为抄袭。在这种情况下,人类设计师可以专注于打磨自己的风格,训练一个专属于自己的模型,使得AI成为他们个性化创作的助手。
这大致是我们在美术领域的应用逻辑。
在音乐领域,我们的工作重点可以概括为“交互式”这三个字。
交互式的核心在于可控性,我们能够实现非常精细的控制,如果某部分效果不尽如人意,可以立即进行调整。
这种交互式的方法涵盖了AI音乐制作的多个方面,包括作词、作曲、伴奏制作以及人声合成。我们都为此开发了相应的工具,使得音乐创作过程不仅高效,而且可以细致调控。
以2021年世界大学生运动会的宣传歌曲为例,这首歌曲的歌词、旋律、伴奏以及演唱部分完全由AI完成。三年前的AI音乐制作水平,已经能够满足常规的宣传和商业用途的需求,并且支持精细的控制和调整。
此外,我们还开发了AI智能体,也就是游戏中的Agent。
三、生成式AI如何改造教育和文旅?实时控制音乐创作,提供多模态互动体验
在讨论AI安全的同时,我们回到今天的主题,探讨生成式AI在教育和文旅领域的应用。
在教育领域,尤其是在音乐教育方面,传统的教学方法往往侧重于演奏和演唱这两个考核指标。学生通常需要演奏一首指定的曲目,相似度高则通过考核,否则需要回去继续练习。
然而,随着素质教育和美育教育的推广,国家的教学大纲开始强调音乐鉴赏和音乐创作两部分内容。音乐创作对于教学来说是一个挑战,但有了生成式AI的帮助,我们可以快速地将其融入教学过程中,并且可以与国学文化相结合。
例如,许多唐诗宋词原本就是吟唱的,但现代人往往不知道如何唱。利用AI,我们可以生成相应的曲调,如果觉得生成的旋律不够理想,AI还能够提供细粒度的调整建议,从而创造出千人千面的旋律。孩子们可以跟着这些旋律学唱,这样既能学习音乐,又能在不知不觉中背诵古诗。
除了音乐创作,AI还可以用于教授音乐理论知识,如旋律曲线的绘制,AI可以根据用户绘制的线条生成相应的旋律。
旋律曲线的绘制是音乐创作中的一个重要知识点,通过AI的辅助,学生可以通过简单的点击鼠标来体验音乐创作的过程,并学习相关的音乐理论知识,如同头异尾、模进等概念,同时还能进行音阶和节奏的训练。
在实际应用场景中,一些学校已经建立了美育教室,学生可以在这样的教室中学习音乐创作和鉴赏,探索如何使音乐更加悦耳动听。
这个系统不仅多次被央视报道,而且在全国范围得到了推广,包括成都、上海、北京等地区的美术教育中也都有所应用。通过这些创新的教学工具和方法,AI正在帮助教育者以更互动和沉浸式的方式进行教学,提高学习效率,同时也为学生带来了全新的学习体验。
什么叫交互式?交互式是指通过互动的方式进行沟通或教学,从而获得更个性化和动态的体验。
在AI音乐创作的例子中,交互式不仅指用户可以实时调整和控制音乐创作的各个方面,也意味着可以通过AI生成的内容来教育和引导。例如,通过一个AI生成的小游戏来教育小朋友如何应对校园霸凌。在这个游戏中,孩子们可以身临其境地体验故事情节,学习在不同情况下如何应对和求助,这样的交互式体验比传统的讲授方式更加生动和有效。
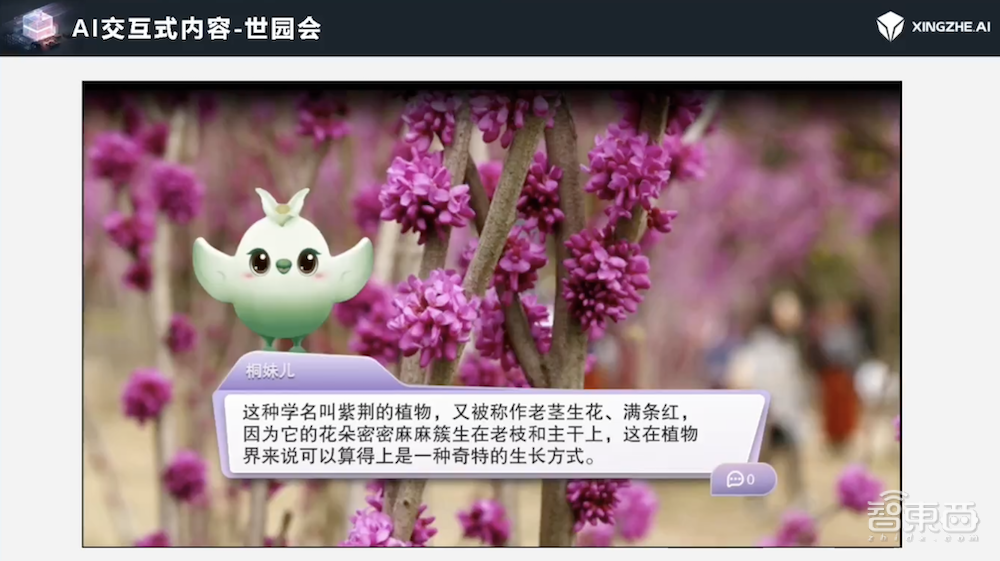
与世界园艺博览会的合作也是采用了类似的方法。通过AI技术,用户可以快速生成一个包含世园会中上万种植物信息的互动体验,每个植物都有详细的介绍,所有的图像、角色、声音和交互环节都是由AI生成的。
此外,AI还被用于与传统文化的结合。例如与中国皮影戏博物馆的合作案例,参观者可以在博物馆中通过摄像头拍摄自己的照片,AI将根据这些照片生成个人的皮影形象,并允许用户在皮影戏的虚拟世界中进行互动。这种体验不仅增强了对传统文化的了解,还通过AI的实时生成技术,让每次的体验都是独一无二的。
AI技术也被应用于城市特色体验的生成,如在成都可以生成以雪山为远景、成都街景为近景的文化体验,在广州可以生成小蛮腰,在上海市可以生成东方明珠。这些体验都是可以交互的,而且随着进入博物馆的人数增加,皮影戏中的角色也会相应增加,从而改变了传统的沉浸式体验模式。
传统的沉浸式体验内容更新周期长,游客体验后可能就不会再次回访。但通过AI技术,可以实现快速实时的内容更新,使得每次访问都有新的体验。AI可以生成365天都不重样的沉浸式体验,每天都有新的内容和互动,极大地提升了重游价值和文化体验的深度。
AI技术与自贡宫灯会的结合,展示了AI在多语言交流和互动娱乐方面的应用。通过使用Agent和多样的AIGC技术,宫灯会的AI角色不仅能够使用多国语言与观众进行对话,还能驱动3D模型与观众进行互动。这些AI角色可以根据不同的国家和地区使用相应的语言进行交流,不仅能进行对话,还能唱歌和跳舞,为观众提供丰富的多模态体验。
例如,如果今天要感谢“智东西”和“智猩猩”的邀请,只需将这两个名字输入AI系统,AI形象便可以根据输入进行相应的表演。
这些都是AI技术具体落地的应用场景,体现了交互式多模态体验的潜力。
此外,AI技术在文旅场景中的应用也非常广泛。在许多文旅景点,由于人多,找到一个好的拍照位置并不容易,而且晚上的灯会等场景虽然景色迷人,但拍摄人物照片时往往因为光线问题导致面部暗淡。AI写真打卡功能可以轻松解决这一问题,它不仅能够美化照片背景,还能提升人物形象的亮度和清晰度。
AI技术还可以用于生成与植物相结合的抽象画,这些画作在现实中很难拍摄出来,但通过AI的生成能力,用户可以创造出独特的艺术效果。更进一步,如果现场有打印机,观众可以将这些AI生成的画作打印出来并带回家,极大地增强了参观体验。
以上是尹学渊演讲内容的完整整理。